Lay Perceptions of Crowd-Scientific Findings
The Risks of Variability and Lack of Consensus
Shilaan Alzahawi & Benoît Monin
Hi, thank you for being here. Today I'll present some recent findings on crowdsourcing data analysis that I've been working on in collaboration with my co-author Professor Benoit Monin.
Outline
First, I'll share a brief open science statement and links to all the available materials. Then, I'll define crowd science.
First, I'll share a brief open science statement and links to all the available materials. Then, I'll define crowd science.
First, I'll share a brief open science statement and links to all the available materials. Then, I'll define crowd science.
Then, I'll define crowd science and crowdsourced data analysis and introduce our question of interest, which is "does crowdsourcing data analysis improve lay perceptions of scientific findings?".
First, I'll share a brief open science statement and links to all the available materials. Then, I'll define crowd science.
Then, I'll define crowd science and crowdsourced data analysis and introduce our question of interest, which is "does crowdsourcing data analysis improve lay perceptions of scientific findings?".
First, I'll share a brief open science statement and links to all the available materials. Then, I'll define crowd science.
Then, I'll define crowd science and crowdsourced data analysis and introduce our question of interest, which is "does crowdsourcing data analysis improve lay perceptions of scientific findings?".
First, I'll share a brief open science statement and links to all the available materials. Then, I'll define crowd science.
Then, I'll define crowd science and crowdsourced data analysis and introduce our question of interest, which is "does crowdsourcing data analysis improve lay perceptions of scientific findings?".
First, I'll share a brief open science statement and links to all the available materials. Then, I'll define crowd science.
Then, I'll define crowd science and crowdsourced data analysis and introduce our question of interest, which is "does crowdsourcing data analysis improve lay perceptions of scientific findings?".
Afterwards we'll briefly talk about the methods and results of an experiment, and hopefully we'll have some time at the end for some discussion.
First, I'll share a brief open science statement and links to all the available materials. Then, I'll define crowd science.
Then, I'll define crowd science and crowdsourced data analysis and introduce our question of interest, which is "does crowdsourcing data analysis improve lay perceptions of scientific findings?".
Afterwards we'll briefly talk about the methods and results of an experiment, and hopefully we'll have some time at the end for some discussion.
If you have any questions, thoughts, comments, please feel free to raise your hand or unmute yourself and jump in. We have quite some time today for this session, so I'd be happy to make this as interactive as you'd like it to be.
Open Science Statement
Open Science Statement
Open Science Statement
Open Science Statement
github.com/shilaan/many-analysts
Slides at bit.ly/many-analysts
Artwork by @allison_horst
In terms of the materials, these are all available online, including a preregistration, the survey, data and code, and a fully reproducible manuscript. You can find all these materials on the OSF and on Github, and you can also find these slides online if you want to have them in front of you at bit.ly/many-analysts.
Crowdsourcing Science
Crowd Science
Crowd Science
The organization of scientific research in open and collaborative projects
Crowd Science
The organization of scientific research in open and collaborative projects
From highly inclusive (sourcing citizens) to highly selective (sourcing specialists)
Crowd Science
The organization of scientific research in open and collaborative projects
From highly inclusive (sourcing citizens) to highly selective (sourcing specialists)
Used at different stages of the research process
You may have already heard of crowdfunding, which uses the crowd for funding, but you can also use a crowd of individuals for generating research ideas, designing studies, collecting data, and analyzing data, which is what I'll be talking about today.
Crowd Science
The organization of scientific research in open and collaborative projects
From highly inclusive (sourcing citizens) to highly selective (sourcing specialists)
Used at different stages of the research process
Funding
Ideation
Study design
Data collection
Data analysis
Writing
Peer review
Replication
You may have already heard of crowdfunding, which uses the crowd for funding, but you can also use a crowd of individuals for generating research ideas, designing studies, collecting data, and analyzing data, which is what I'll be talking about today.
Crowd Science
The organization of scientific research in open and collaborative projects
From highly inclusive (sourcing citizens) to highly selective (sourcing specialists)
Used at different stages of the research process
Funding
Ideation
Study design
Data collection
Data analysis
Writing
Peer review
Replication
The great meteor storm of 1833: birth of Citizen Science
In 1833, Denison Olmsted used letter correspondence to recruit citizen scientists to help document a meteor shower. This led to a detailed documentation of the great meteor shower and the birth of the citizen-science movement (highly inclusive, used for data collection. In terms of the two dimensions we just discussed, this project can be categorized as highly inclusive - because it sourced citizens - and as used in the stage of data collection.
Crowdsourcing Data Analysis
Crowdsourced Data Analysis
Involves giving different teams of scientists the same dataset, who independently analyze it to answer the same research question or estimate and report on a parameter of interest.
Crowdsourced Data Analysis
Different teams of scientists independently analyze the same dataset
Involves giving different teams of scientists the same dataset, who independently analyze it to answer the same research question or estimate and report on a parameter of interest.
Crowdsourced Data Analysis
Different teams of scientists independently analyze the same dataset
Also known as the many-analysts or multi-analyst approach
Involves giving different teams of scientists the same dataset, who independently analyze it to answer the same research question or estimate and report on a parameter of interest.
Crowdsourced Data Analysis
Different teams of scientists independently analyze the same dataset
Also known as the many-analysts or multi-analyst approach
On the rise in the social and behavioral sciences
Involves giving different teams of scientists the same dataset, who independently analyze it to answer the same research question or estimate and report on a parameter of interest.
Crowdsourced Data Analysis
Different teams of scientists independently analyze the same dataset
Also known as the many-analysts or multi-analyst approach
On the rise in the social and behavioral sciences
| Author | Year | Title | |
|---|---|---|---|
| 1 | Breznau et al. | 2021 | How many replicators does it take to achieve reliability? Investigating researcher variability in a crowdsourced replication |
| 2 | Breznau et al. | 2021 | Observing many researchers using the same data and hypothesis reveals a hidden universe of uncertainty |
Involves giving different teams of scientists the same dataset, who independently analyze it to answer the same research question or estimate and report on a parameter of interest.
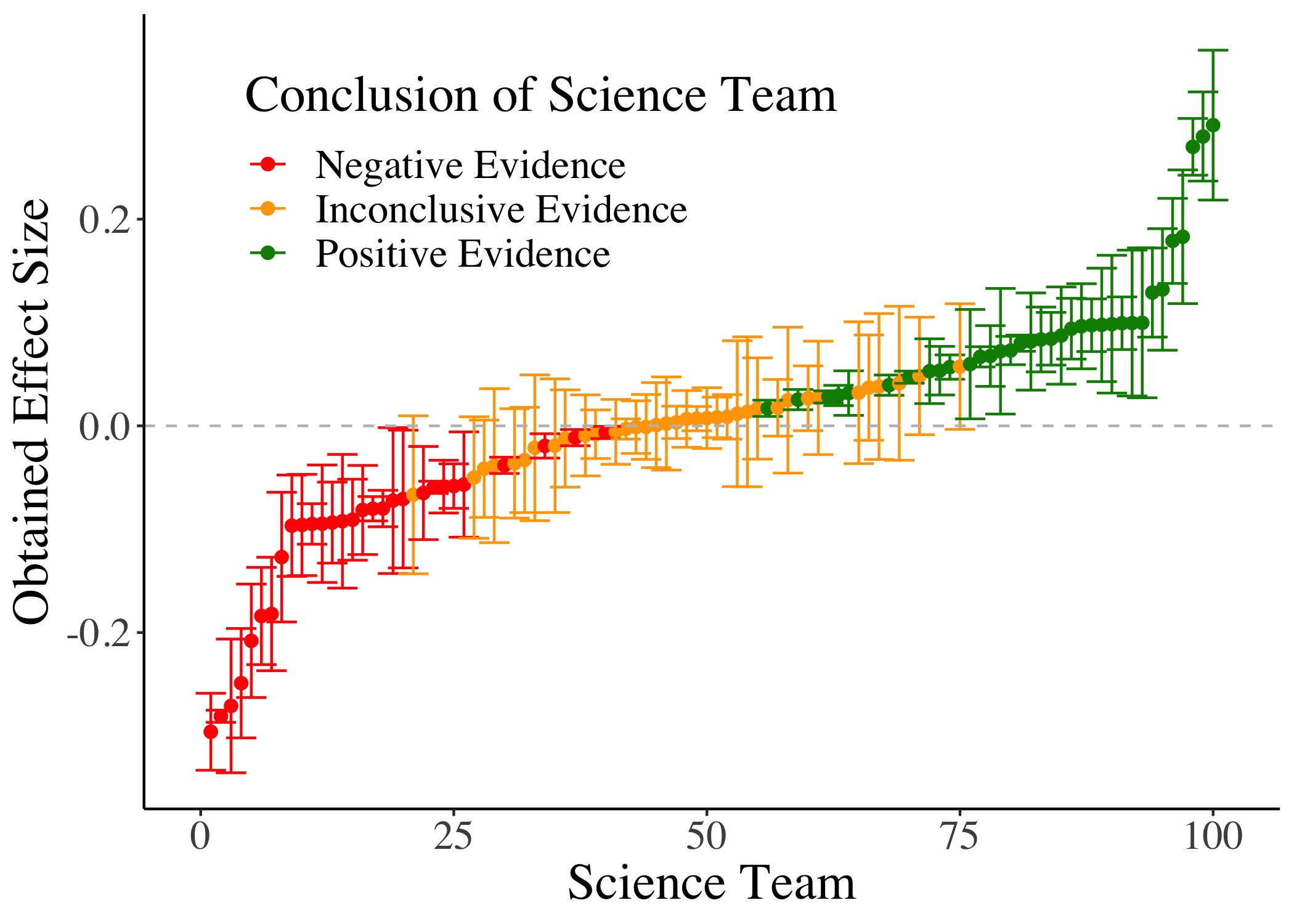
I'm including an interactive table with 7 papers that have recently been published in the social and behavioral science that use the many-analyst approach. They include interesting topics such as variability in replications, opinions about different social policies, the effects of the gender and professional status of scientists on their verbosity during group meetings, variability in the analysis of fmri (so neuroimaging datasets), and we can scroll back all the way to 2018, to a quite well-known study that looked at discrimination against darker skin toned soccer players, and arguably started the recent crowd science movement in behavioral science.
The Rationale of Crowdsourced Data Analysis
What is the rationale of crowdsourced data analysis - why should we be convinced by its findings? The phenomenon that underlies crowd science in general is known as the wisdom of the crowd.
The Rationale of Crowdsourced Data Analysis
The Wisdom of the Crowd
What is the rationale of crowdsourced data analysis - why should we be convinced by its findings? The phenomenon that underlies crowd science in general is known as the wisdom of the crowd.
The Rationale of Crowdsourced Data Analysis
The Wisdom of the Crowd
Individual judgments are associated with idiosyncratic noise
What is the rationale of crowdsourced data analysis - why should we be convinced by its findings? The phenomenon that underlies crowd science in general is known as the wisdom of the crowd.
The Rationale of Crowdsourced Data Analysis
The Wisdom of the Crowd
Individual judgments are associated with idiosyncratic noise
Averaging over many judgments can cancel some of that noise
What is the rationale of crowdsourced data analysis - why should we be convinced by its findings? The phenomenon that underlies crowd science in general is known as the wisdom of the crowd.
The Rationale of Crowdsourced Data Analysis
The Wisdom of the Crowd
Individual judgments are associated with idiosyncratic noise
Averaging over many judgments can cancel some of that noise
In 1906, 787 people guessed the weight of an ox at a farmers' fair...
The mean of all guesses was exactly equal to the true value
The mean outperformed the estimates of experts
The mean outperformed the individual best guesser
Perhaps the first documented case of the wisdom of the crowd was back in 1906, when... 1197 pounds, cattle experts, individual best guesser who took home the grand prize that day.
This may seem unsurprising now, but it wasn't back then. Back then, the fact that crowds were wise was a surprise. Crowds mostly had negative associations, were referred to as mobs, and there was heated intellectual debate about restricting the right to vote to intellectuals, rather than democratizing society.
To benefit from the wisdom of crowds several conditions must be in place. First each individual member of the crowd must have their own independent source of information. Second they must make individual decisions and not be swayed by the decisions of those around them. And third, there must be a mechanism in place that can collate these diverse opinions.
Benefits of Crowdsourced Data Analysis
Crowdsourced data analysis can help to...
I'll mention some benefits, some of which will overlap, and most of them are intimately related with each other.
Benefits of Crowdsourced Data Analysis
Crowdsourced data analysis can help to...
Diversify contributions to research
I'll mention some benefits, some of which will overlap, and most of them are intimately related with each other.
First, crowdsourced data analysis can help to diversify contributions to research. I will say that this benefit is not specific to crowdsourcing data analysis, but a property of crowd science and big team science in general. A goal of crowd science and big team science is to promote inclusivity and include researchers from underrepresented institutions. This comes with all the benefits of diversity. It allows us to leverage under-used resources and skills. We of course can't all be an expert on everything. If we recruit a diverse sample of data analysts, some may have expertise, for example, on a certain statistical method that is most appropriate for the data at hand, or they'll have some other expertise that may benefit the data analysis.
Benefits of Crowdsourced Data Analysis
Crowdsourced data analysis can help to...
Diversify contributions to research
Expose the inherent variability of results
I'll mention some benefits, some of which will overlap, and most of them are intimately related with each other.
First, crowdsourced data analysis can help to diversify contributions to research. I will say that this benefit is not specific to crowdsourcing data analysis, but a property of crowd science and big team science in general. A goal of crowd science and big team science is to promote inclusivity and include researchers from underrepresented institutions. This comes with all the benefits of diversity. It allows us to leverage under-used resources and skills. We of course can't all be an expert on everything. If we recruit a diverse sample of data analysts, some may have expertise, for example, on a certain statistical method that is most appropriate for the data at hand, or they'll have some other expertise that may benefit the data analysis.
Second, the many-analyst approach helps to acknowledge that results in social science tend to be very variable, and can depend on idiosyncratic choices we have to make among multiple valid approaches, sometimes even choices we make unconsciously, such as the version of statistical software we rely on or the different defaults in for instance SPSS and R: it is important to note that the many-analyst approach does not create this variability in results, it simply exposes it. that should give us pause and epistemic humility when we assess conventional scientific research, which is often done by a single analyst or a single team: the particular outcome you're looking at is one from a distribution of outcomes that could have been possible, if the analyst had made different choices.
Like Nicholas said in his opening talk, approaches like this allow us to explore the size of the multiverse.
Benefits of Crowdsourced Data Analysis
Crowdsourced data analysis can help to...
Diversify contributions to research
Expose the inherent variability of results
Assess the impact of individual analytic choices on the results
I'll mention some benefits, some of which will overlap, and most of them are intimately related with each other.
First, crowdsourced data analysis can help to diversify contributions to research. I will say that this benefit is not specific to crowdsourcing data analysis, but a property of crowd science and big team science in general. A goal of crowd science and big team science is to promote inclusivity and include researchers from underrepresented institutions. This comes with all the benefits of diversity. It allows us to leverage under-used resources and skills. We of course can't all be an expert on everything. If we recruit a diverse sample of data analysts, some may have expertise, for example, on a certain statistical method that is most appropriate for the data at hand, or they'll have some other expertise that may benefit the data analysis.
Second, the many-analyst approach helps to acknowledge that results in social science tend to be very variable, and can depend on idiosyncratic choices we have to make among multiple valid approaches, sometimes even choices we make unconsciously, such as the version of statistical software we rely on or the different defaults in for instance SPSS and R: it is important to note that the many-analyst approach does not create this variability in results, it simply exposes it. that should give us pause and epistemic humility when we assess conventional scientific research, which is often done by a single analyst or a single team: the particular outcome you're looking at is one from a distribution of outcomes that could have been possible, if the analyst had made different choices.
Like Nicholas said in his opening talk, approaches like this allow us to explore the size of the multiverse.
Third, we can assess the impact of individual analytic choices on the results. Here, we can ask if we can explain the strength of the evidence obtained by the specific individual decisions that researchers make. For instance, we can asses the impact of including or excluding certain control variables, the impact of running a certain statistical model such as a t-test or a mixed effects model, or the impact of excluding or including certain participants or outliers. We could ask, for example, if people who obtain stronger evidence are more likely to do one or the other, and vice versa.
Benefits of Crowdsourced Data Analysis
Crowdsourced data analysis can help to...
Diversify contributions to research
Expose the inherent variability of results
Assess the impact of individual analytic choices on the results
Assess the overall analytic robustness of a finding
I'll mention some benefits, some of which will overlap, and most of them are intimately related with each other.
First, crowdsourced data analysis can help to diversify contributions to research. I will say that this benefit is not specific to crowdsourcing data analysis, but a property of crowd science and big team science in general. A goal of crowd science and big team science is to promote inclusivity and include researchers from underrepresented institutions. This comes with all the benefits of diversity. It allows us to leverage under-used resources and skills. We of course can't all be an expert on everything. If we recruit a diverse sample of data analysts, some may have expertise, for example, on a certain statistical method that is most appropriate for the data at hand, or they'll have some other expertise that may benefit the data analysis.
Second, the many-analyst approach helps to acknowledge that results in social science tend to be very variable, and can depend on idiosyncratic choices we have to make among multiple valid approaches, sometimes even choices we make unconsciously, such as the version of statistical software we rely on or the different defaults in for instance SPSS and R: it is important to note that the many-analyst approach does not create this variability in results, it simply exposes it. that should give us pause and epistemic humility when we assess conventional scientific research, which is often done by a single analyst or a single team: the particular outcome you're looking at is one from a distribution of outcomes that could have been possible, if the analyst had made different choices.
Like Nicholas said in his opening talk, approaches like this allow us to explore the size of the multiverse.
Third, we can assess the impact of individual analytic choices on the results. Here, we can ask if we can explain the strength of the evidence obtained by the specific individual decisions that researchers make. For instance, we can asses the impact of including or excluding certain control variables, the impact of running a certain statistical model such as a t-test or a mixed effects model, or the impact of excluding or including certain participants or outliers. We could ask, for example, if people who obtain stronger evidence are more likely to do one or the other, and vice versa.
Fourth, the many-analyst approach can help us assess the overall analytic robustness of a finding. We can assess to what extent a finding holds across many different analytic specification. We can ask: do the results come out consistently positive, or consistently negative, across different independent analyses?
Benefits of Crowdsourced Data Analysis
Crowdsourced data analysis can help to...
Diversify contributions to research
Expose the inherent variability of results
Assess the impact of individual analytic choices on the results
Assess the overall analytic robustness of a finding
Increase confidence when independent analyses yield the same conclusion
I'll mention some benefits, some of which will overlap, and most of them are intimately related with each other.
First, crowdsourced data analysis can help to diversify contributions to research. I will say that this benefit is not specific to crowdsourcing data analysis, but a property of crowd science and big team science in general. A goal of crowd science and big team science is to promote inclusivity and include researchers from underrepresented institutions. This comes with all the benefits of diversity. It allows us to leverage under-used resources and skills. We of course can't all be an expert on everything. If we recruit a diverse sample of data analysts, some may have expertise, for example, on a certain statistical method that is most appropriate for the data at hand, or they'll have some other expertise that may benefit the data analysis.
Second, the many-analyst approach helps to acknowledge that results in social science tend to be very variable, and can depend on idiosyncratic choices we have to make among multiple valid approaches, sometimes even choices we make unconsciously, such as the version of statistical software we rely on or the different defaults in for instance SPSS and R: it is important to note that the many-analyst approach does not create this variability in results, it simply exposes it. that should give us pause and epistemic humility when we assess conventional scientific research, which is often done by a single analyst or a single team: the particular outcome you're looking at is one from a distribution of outcomes that could have been possible, if the analyst had made different choices.
Like Nicholas said in his opening talk, approaches like this allow us to explore the size of the multiverse.
Third, we can assess the impact of individual analytic choices on the results. Here, we can ask if we can explain the strength of the evidence obtained by the specific individual decisions that researchers make. For instance, we can asses the impact of including or excluding certain control variables, the impact of running a certain statistical model such as a t-test or a mixed effects model, or the impact of excluding or including certain participants or outliers. We could ask, for example, if people who obtain stronger evidence are more likely to do one or the other, and vice versa.
Fourth, the many-analyst approach can help us assess the overall analytic robustness of a finding. We can assess to what extent a finding holds across many different analytic specification. We can ask: do the results come out consistently positive, or consistently negative, across different independent analyses?
And when we do find that the result come out consistently positive or negative, then this can increase our confidence in the specific conclusion we're drawing.
Benefits of Crowdsourced Data Analysis
Crowdsourced data analysis can help to...
Diversify contributions to research
Expose the inherent variability of results
Assess the impact of individual analytic choices on the results
Assess the overall analytic robustness of a finding
Increase confidence when independent analyses yield the same conclusion
Average across idiosyncratic analytic choices to obtain more accurate parameter estimates
I'll mention some benefits, some of which will overlap, and most of them are intimately related with each other.
First, crowdsourced data analysis can help to diversify contributions to research. I will say that this benefit is not specific to crowdsourcing data analysis, but a property of crowd science and big team science in general. A goal of crowd science and big team science is to promote inclusivity and include researchers from underrepresented institutions. This comes with all the benefits of diversity. It allows us to leverage under-used resources and skills. We of course can't all be an expert on everything. If we recruit a diverse sample of data analysts, some may have expertise, for example, on a certain statistical method that is most appropriate for the data at hand, or they'll have some other expertise that may benefit the data analysis.
Second, the many-analyst approach helps to acknowledge that results in social science tend to be very variable, and can depend on idiosyncratic choices we have to make among multiple valid approaches, sometimes even choices we make unconsciously, such as the version of statistical software we rely on or the different defaults in for instance SPSS and R: it is important to note that the many-analyst approach does not create this variability in results, it simply exposes it. that should give us pause and epistemic humility when we assess conventional scientific research, which is often done by a single analyst or a single team: the particular outcome you're looking at is one from a distribution of outcomes that could have been possible, if the analyst had made different choices.
Like Nicholas said in his opening talk, approaches like this allow us to explore the size of the multiverse.
Third, we can assess the impact of individual analytic choices on the results. Here, we can ask if we can explain the strength of the evidence obtained by the specific individual decisions that researchers make. For instance, we can asses the impact of including or excluding certain control variables, the impact of running a certain statistical model such as a t-test or a mixed effects model, or the impact of excluding or including certain participants or outliers. We could ask, for example, if people who obtain stronger evidence are more likely to do one or the other, and vice versa.
Fourth, the many-analyst approach can help us assess the overall analytic robustness of a finding. We can assess to what extent a finding holds across many different analytic specification. We can ask: do the results come out consistently positive, or consistently negative, across different independent analyses?
And when we do find that the result come out consistently positive or negative, then this can increase our confidence in the specific conclusion we're drawing.
And going back to the wisdom of the crowd phenomenon that we discussed, another benefit is that we can average across all these idiosyncratic analytic choices to obtain more accurate parameter estimates and to balance out individual biases and errors in the aggregate
Benefits of Crowdsourced Data Analysis
Crowdsourced data analysis can help to...
Diversify contributions to research
Expose the inherent variability of results
Assess the impact of individual analytic choices on the results
Assess the overall analytic robustness of a finding
Increase confidence when independent analyses yield the same conclusion
Average across idiosyncratic analytic choices to obtain more accurate parameter estimates
... and to balance out individual biases and errors in the aggregate
I'll mention some benefits, some of which will overlap, and most of them are intimately related with each other.
First, crowdsourced data analysis can help to diversify contributions to research. I will say that this benefit is not specific to crowdsourcing data analysis, but a property of crowd science and big team science in general. A goal of crowd science and big team science is to promote inclusivity and include researchers from underrepresented institutions. This comes with all the benefits of diversity. It allows us to leverage under-used resources and skills. We of course can't all be an expert on everything. If we recruit a diverse sample of data analysts, some may have expertise, for example, on a certain statistical method that is most appropriate for the data at hand, or they'll have some other expertise that may benefit the data analysis.
Second, the many-analyst approach helps to acknowledge that results in social science tend to be very variable, and can depend on idiosyncratic choices we have to make among multiple valid approaches, sometimes even choices we make unconsciously, such as the version of statistical software we rely on or the different defaults in for instance SPSS and R: it is important to note that the many-analyst approach does not create this variability in results, it simply exposes it. that should give us pause and epistemic humility when we assess conventional scientific research, which is often done by a single analyst or a single team: the particular outcome you're looking at is one from a distribution of outcomes that could have been possible, if the analyst had made different choices.
Like Nicholas said in his opening talk, approaches like this allow us to explore the size of the multiverse.
Third, we can assess the impact of individual analytic choices on the results. Here, we can ask if we can explain the strength of the evidence obtained by the specific individual decisions that researchers make. For instance, we can asses the impact of including or excluding certain control variables, the impact of running a certain statistical model such as a t-test or a mixed effects model, or the impact of excluding or including certain participants or outliers. We could ask, for example, if people who obtain stronger evidence are more likely to do one or the other, and vice versa.
Fourth, the many-analyst approach can help us assess the overall analytic robustness of a finding. We can assess to what extent a finding holds across many different analytic specification. We can ask: do the results come out consistently positive, or consistently negative, across different independent analyses?
And when we do find that the result come out consistently positive or negative, then this can increase our confidence in the specific conclusion we're drawing.
And going back to the wisdom of the crowd phenomenon that we discussed, another benefit is that we can average across all these idiosyncratic analytic choices to obtain more accurate parameter estimates and to balance out individual biases and errors in the aggregate
Lay Perceptions
Now I'd like to move on to talking about lay perceptions. One of the reasons crowdsourced data analysis was proposed, was to increase the credibility of scientific research. Now, we know there's quite a great deal of science skepticism in some public circles, so we want scientific research to become more credible not just to ourselves as academics, but to lay people as well.
Lay Perceptions of Crowd-Scientific Findings
According to its proponents, crowdsourcing data analysis should improve lay perceptions of scientific findings
Lay Perceptions of Crowd-Scientific Findings
According to its proponents, crowdsourcing data analysis should improve lay perceptions of scientific findings
| Author | Year | Quote | |
|---|---|---|---|
| 1 | Arbon et al. | 2019 | "For the public to have faith in the conclusions of scientists it is important that the methods they employ are robust and transparent. This study will examine robustness by recruiting teams of independent data analysts and looking at how they answer a controversial research question using the same data, effectively ‘crowd-sourcing’ the data analysis." |
| 2 | Breznau | 2021 | "crowdsourcing provides a new way to increase credibility for political and social research—in both sample populations and among the researchers themselves (…) It is hoped that these developments are tangible outcomes that increase public, private, and government views of social science." |
| 3 | Breznau et al. | 2021 | "Organized scientific knowledge production (…) should generate inter-researcher reliability, offering consumers of scientific findings assurance that they are not arbitrary flukes but that other researchers would generate similar findings given the same data." |
I'm including here another table with three quotes. The first one is from a preregistration, in which the authors justify their use of the many-analyst approach by referring to the public needing to have faith in the conclusions of scientists. The second one is from a commentary on the many-analyst approach, in which the author provides the hopeful view that crowdsourcing provides a new way to increase credibility for social research, not just among researchers themselves, but in sample populations as well; and that it's hoped that the many-analyst approach will increase public views of social science. The third one is from a preprint relying on the many-analyst approach, in which the authors argue that many-analyst studies that generate consistent results across independent analysis should offer consumers of scientific findings assurance that they are not arbitrary flukes.
Does Crowdsourcing Data Analysis Improve the Credibility of Scientific Findings
Now, these quotes describe a worthy goal: improving the credibility of scientific findings through crowdsourcing data analysis. However, this is also an empirical claim, and as far as we know there is no evidence yet that crowdsourcing data analysis can indeed achieve this goal. So that's what we'll be looking at today: does crowdsourcing data analysis improve lay perceptions of scientific findings?
Method
Method
Method
We run an experiment with three conditions
Three scenarios. The first condition is a conventional, single-analyst condition where a single team of six scientists analyzes the same dataset and reports a single, aggregrate parameter estimate of 5% for the relationship between two variables that I'll introduce shortly.
Method
We run an experiment with three conditions
Single-analyst a single, aggregate parameter estimate
Three scenarios. The first condition is a conventional, single-analyst condition where a single team of six scientists analyzes the same dataset and reports a single, aggregrate parameter estimate of 5% for the relationship between two variables that I'll introduce shortly.
We contrast this condition with two multi-analyst conditions. In the multi-consistent conditon, six independent teams of scientists report six independent estimates that show low variance and high consensus: they all agree in their conclusion, and the spread in their effect size estimate is small.
Method
We run an experiment with three conditions
Single-analyst a single, aggregate parameter estimate
Multi-consistent multiple parameter estimates with low variance and high consensus
Three scenarios. The first condition is a conventional, single-analyst condition where a single team of six scientists analyzes the same dataset and reports a single, aggregrate parameter estimate of 5% for the relationship between two variables that I'll introduce shortly.
We contrast this condition with two multi-analyst conditions. In the multi-consistent conditon, six independent teams of scientists report six independent estimates that show low variance and high consensus: they all agree in their conclusion, and the spread in their effect size estimate is small.
In the multi-consistent condition, six independent teams of scientists report six independent estimates that show high variance and low consensus. There is a large spread between the estimates, and the qualitative conclusions differ: two of the scientists find a negative relationship, and four of the scientists find a positive relationship.
Method
We run an experiment with three conditions
Single-analyst a single, aggregate parameter estimate
Multi-consistent multiple parameter estimates with low variance and high consensus
Multi-inconsistent multiple parameter estimates with high variance and low consensus
Three scenarios. The first condition is a conventional, single-analyst condition where a single team of six scientists analyzes the same dataset and reports a single, aggregrate parameter estimate of 5% for the relationship between two variables that I'll introduce shortly.
We contrast this condition with two multi-analyst conditions. In the multi-consistent conditon, six independent teams of scientists report six independent estimates that show low variance and high consensus: they all agree in their conclusion, and the spread in their effect size estimate is small.
In the multi-consistent condition, six independent teams of scientists report six independent estimates that show high variance and low consensus. There is a large spread between the estimates, and the qualitative conclusions differ: two of the scientists find a negative relationship, and four of the scientists find a positive relationship.
Method
We run an experiment with three conditions
Single-analyst a single, aggregate parameter estimate
Multi-consistent multiple parameter estimates with low variance and high consensus
Multi-inconsistent multiple parameter estimates with high variance and low consensus
In all three conditions, the given estimates average to 5%. We study the effects on
Posterior beliefs about the reported phenomenon
Credibility of the results
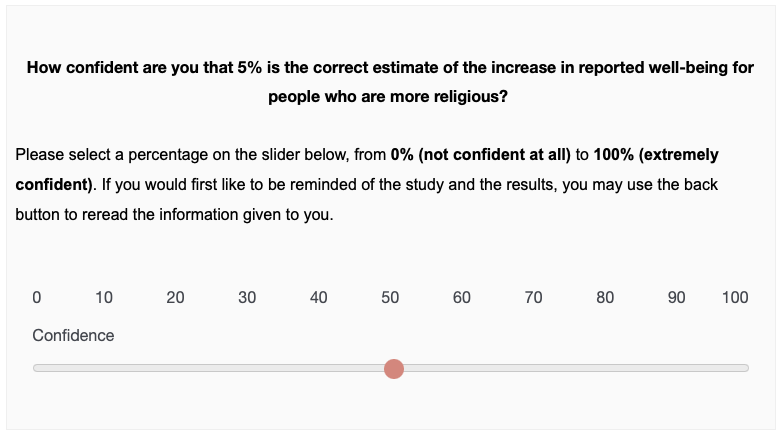
Confidence in the aggregate estimate of 5%
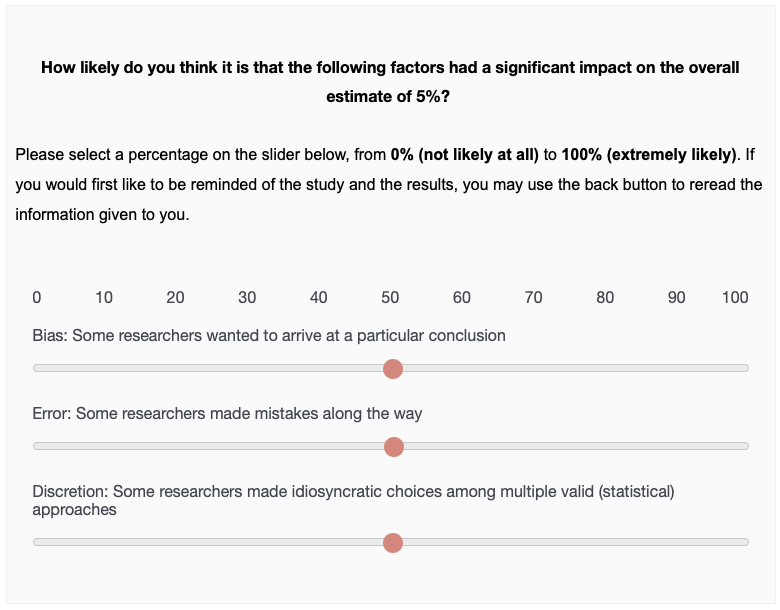
Perceived impact of bias on the 5% estimate
Perceived impact of error on the 5% estimate
Perceived impact of discretion on the 5% estimate
Three scenarios. The first condition is a conventional, single-analyst condition where a single team of six scientists analyzes the same dataset and reports a single, aggregrate parameter estimate of 5% for the relationship between two variables that I'll introduce shortly.
We contrast this condition with two multi-analyst conditions. In the multi-consistent conditon, six independent teams of scientists report six independent estimates that show low variance and high consensus: they all agree in their conclusion, and the spread in their effect size estimate is small.
In the multi-consistent condition, six independent teams of scientists report six independent estimates that show high variance and low consensus. There is a large spread between the estimates, and the qualitative conclusions differ: two of the scientists find a negative relationship, and four of the scientists find a positive relationship.
In all three conditions the estimates average to 5%
Experimental design
Experimental design
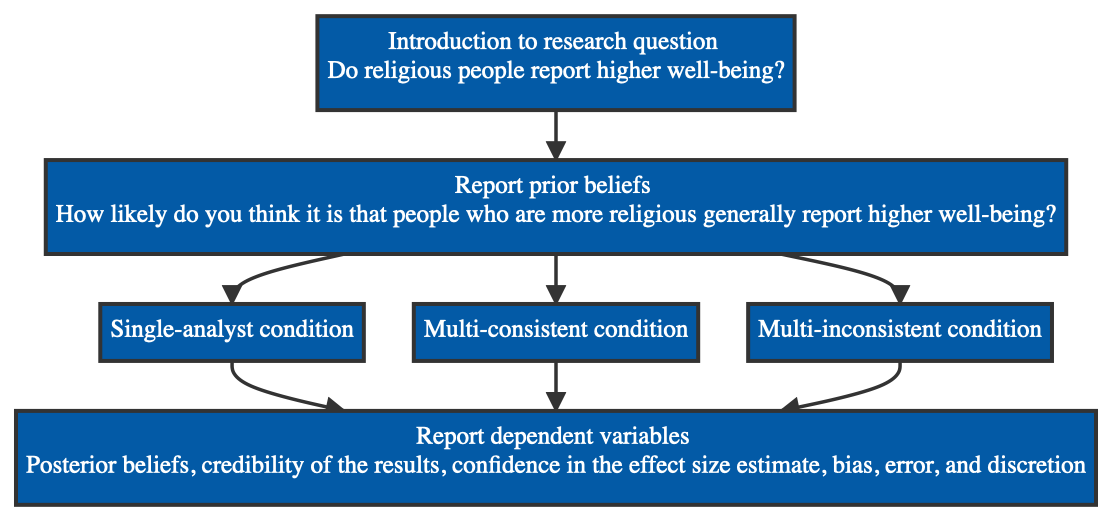
In terms of the experimental design, participants are first introduced to a research question - do religious people report higher well-being - and then report their prior beliefs about this research question. They are then allocated to one of the three conditions, and afterwards report the outcomes that I just described.
Hypotheses
Social norms theory
Observing consensus among a crowd increases conformity in opinion
We based our hypotheses on three lines of thought. First, in line with social norms theory, we expect that observing consensus among a crowd (the consistent crowd condition) will -- compared to the conclusion of a single scientist (the single estimate condition) -- increase conformity in opinion.
Hypotheses
Social norms theory
Observing consensus among a crowd increases conformity in opinion
Intuitive statistics
Observers intuitively accord to the logic of the wisdom of crowds:
The ability of an aggregate of estimates to reduce noise stemming from individual bias or error
We based our hypotheses on three lines of thought. First, in line with social norms theory, we expect that observing consensus among a crowd (the consistent crowd condition) will -- compared to the conclusion of a single scientist (the single estimate condition) -- increase conformity in opinion.
We based our hypotheses on three lines of thought. First, in line with social norms theory, we expect that observing consensus among a crowd (the consistent crowd condition) will -- compared to the conclusion of a single scientist (the single estimate condition) -- increase conformity in opinion.
Second, Drawing from work on intuitive statistics, we also expect laypeople to intuitively accord to the logic of "the wisdom of crowds": the ability of an aggregate of estimates (rather than a single estimate) to reduce noise stemming from individual bias or error.
In contrast, when crowd estimates show low consensus and high variance (the inconsistent crowd condition), we predict that observers will be less swayed and more likely to attribute the findings to bias and error.
Hypotheses
Social norms theory
Observing consensus among a crowd increases conformity in opinion
Intuitive statistics
Observers intuitively accord to the logic of the wisdom of crowds:
The ability of an aggregate of estimates to reduce noise stemming from individual bias or error
Aversion to variability
Observing variable estimates decreases confidence in the overall estimate
We based our hypotheses on three lines of thought. First, in line with social norms theory, we expect that observing consensus among a crowd (the consistent crowd condition) will -- compared to the conclusion of a single scientist (the single estimate condition) -- increase conformity in opinion.
We based our hypotheses on three lines of thought. First, in line with social norms theory, we expect that observing consensus among a crowd (the consistent crowd condition) will -- compared to the conclusion of a single scientist (the single estimate condition) -- increase conformity in opinion.
Second, Drawing from work on intuitive statistics, we also expect laypeople to intuitively accord to the logic of "the wisdom of crowds": the ability of an aggregate of estimates (rather than a single estimate) to reduce noise stemming from individual bias or error.
In contrast, when crowd estimates show low consensus and high variance (the inconsistent crowd condition), we predict that observers will be less swayed and more likely to attribute the findings to bias and error.
We based our hypotheses on three lines of thought. First, in line with social norms theory, we expect that observing consensus among a crowd (the consistent crowd condition) will -- compared to the conclusion of a single scientist (the single estimate condition) -- increase conformity in opinion.
Second, Drawing from work on intuitive statistics, we also expect laypeople to intuitively accord to the logic of "the wisdom of crowds": the ability of an aggregate of estimates (rather than a single estimate) to reduce noise stemming from individual bias or error.
In contrast, when crowd estimates show low consensus and high variance (the inconsistent crowd condition), we predict that observers will be less swayed and more likely to attribute the findings to bias and error.
Third, due to the difficulty of lay reasoning about variation, we predict an aversion to variability: i.e., we expect that observing variable estimates will decrease lay confidence in the precise average parameter estimate in both crowd conditions. This is based on the idea that it may be completely foreign to lay consumers that analyzing the dataset can lead to different estimates in the first place. If we report one estimate, this is taken to be the "one true" estimate -- if we report several variable estimates, the consumer in question may no longer be so certain that any of the estimates, or the overall average estimate, is precisely correct.
In sum, our preregistered hypotheses are as follows: when laypeople observe multiple consistent estimates from a crowd of independent scientists, we expect -- compared to a single estimate and controlling for prior beliefs -- higher posterior beliefs and credibility of the results, lower confidence in the precise average parameter estimate, and lower ratings of bias and error. When laypeople observe multiple inconsistent estimates from a crowd of independent scientists, we expect -- compared to a single estimate and controlling for prior beliefs -- lower posterior beliefs and credibility of the results, lower confidence in the precise average parameter estimate, and greater ratings of bias and error.
Hypotheses
Predicted direction of effects
Compared to the single-analyst condition
Controlling for prior beliefs
| Measure | Multi-consistent | Multi-inconsistent |
|---|---|---|
| Posterior beliefs |
We based our hypotheses on three lines of thought. First, in line with social norms theory, we expect that observing consensus among a crowd (the consistent crowd condition) will -- compared to the conclusion of a single scientist (the single estimate condition) -- increase conformity in opinion.
Second, Drawing from work on intuitive statistics, we also expect laypeople to intuitively accord to the logic of "the wisdom of crowds": the ability of an aggregate of estimates (rather than a single estimate) to reduce noise stemming from individual bias or error.
In contrast, when crowd estimates show low consensus and high variance (the inconsistent crowd condition), we predict that observers will be less swayed and more likely to attribute the findings to bias and error.
Third, due to the difficulty of lay reasoning about variation, we predict an aversion to variability: i.e., we expect that observing variable estimates will decrease lay confidence in the precise average parameter estimate in both crowd conditions. In sum, our preregistered hypotheses are as follows: when laypeople observe multiple consistent estimates from a crowd of independent scientists, we expect -- compared to a single estimate and controlling for prior beliefs -- higher posterior beliefs and credibility of the results, lower confidence in the precise average parameter estimate, and lower ratings of bias and error. When laypeople observe multiple inconsistent estimates from a crowd of independent scientists, we expect -- compared to a single estimate and controlling for prior beliefs -- lower posterior beliefs and credibility of the results, lower confidence in the precise average parameter estimate, and greater ratings of bias and error.
Hypotheses
Predicted direction of effects
Compared to the single-analyst condition
Controlling for prior beliefs
| Measure | Multi-consistent | Multi-inconsistent |
|---|---|---|
| Posterior beliefs | ||
| Credibility |
Note. Table indicates the predicted direction of the effect for all dependent variables, compared to the single-analyst condition and controlling for prior beliefs. For example, we hypothesized that, compared to a single-analyst study and controlling for prior beliefs, ratings of credibility would be greater in the multi-analyst: consistent condition and lower in the multi-analyst: inconsistent condition.
Our pre-registered hypotheses can be found in the table: we hypothesized that in the multi-consistent condition (compared to the single-analyst condition), lay consumers would have higher posterior beliefs, would find the results more credible, and would be less likely to believe the results stem from bias or error. For the multi-inconsistent condition, we hypothesized that lay consumers would have lower posterior beliefs, would find the results less credible, and would be more likely to believe the results stem from bias or error. In addition, we expected that the act of providing multiple (slightly to widely varying) parameter estimates would decrease confidence in the aggregate parameter estimate in both multi-analyst conditions.
Hypotheses
Predicted direction of effects
Compared to the single-analyst condition
Controlling for prior beliefs
| Measure | Multi-consistent | Multi-inconsistent |
|---|---|---|
| Posterior beliefs | ||
| Credibility | ||
| Confidence |
Note. Table indicates the predicted direction of the effect for all dependent variables, compared to the single-analyst condition and controlling for prior beliefs. For example, we hypothesized that, compared to a single-analyst study and controlling for prior beliefs, ratings of credibility would be greater in the multi-analyst: consistent condition and lower in the multi-analyst: inconsistent condition.
Hypotheses
Predicted direction of effects
Compared to the single-analyst condition
Controlling for prior beliefs
| Measure | Multi-consistent | Multi-inconsistent |
|---|---|---|
| Posterior beliefs | ||
| Credibility | ||
| Confidence | ||
| Bias |
Note. Table indicates the predicted direction of the effect for all dependent variables, compared to the single-analyst condition and controlling for prior beliefs. For example, we hypothesized that, compared to a single-analyst study and controlling for prior beliefs, ratings of credibility would be greater in the multi-analyst: consistent condition and lower in the multi-analyst: inconsistent condition.
Hypotheses
Predicted direction of effects
Compared to the single-analyst condition
Controlling for prior beliefs
| Measure | Multi-consistent | Multi-inconsistent |
|---|---|---|
| Posterior beliefs | ||
| Credibility | ||
| Confidence | ||
| Bias | ||
| Error |
Note. Table indicates the predicted direction of the effect for all dependent variables, compared to the single-analyst condition and controlling for prior beliefs. For example, we hypothesized that, compared to a single-analyst study and controlling for prior beliefs, ratings of credibility would be greater in the multi-analyst: consistent condition and lower in the multi-analyst: inconsistent condition.
Hypotheses
Predicted direction of effects
Compared to the single-analyst condition
Controlling for prior beliefs
| Measure | Multi-consistent | Multi-inconsistent |
|---|---|---|
| Posterior beliefs | ||
| Credibility | ||
| Confidence | ||
| Bias | ||
| Error | ||
| Discretion | No prediction | No prediction |
Note. Table indicates the predicted direction of the effect for all dependent variables, compared to the single-analyst condition and controlling for prior beliefs. For example, we hypothesized that, compared to a single-analyst study and controlling for prior beliefs, ratings of credibility would be greater in the multi-analyst: consistent condition and lower in the multi-analyst: inconsistent condition.
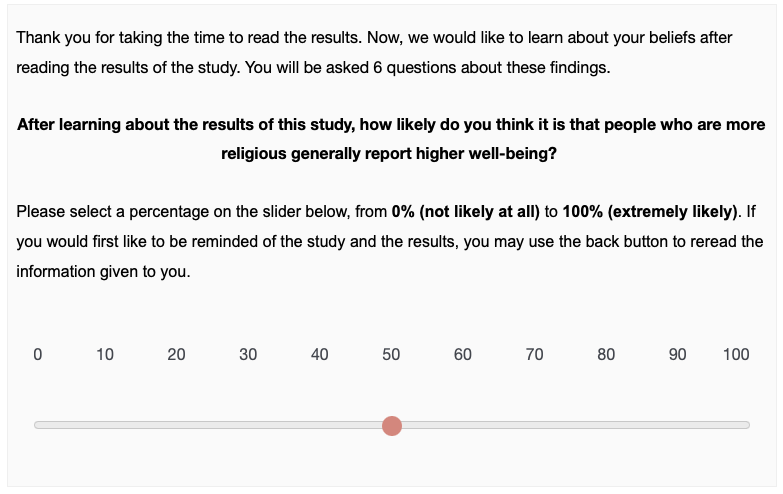
Survey Materials

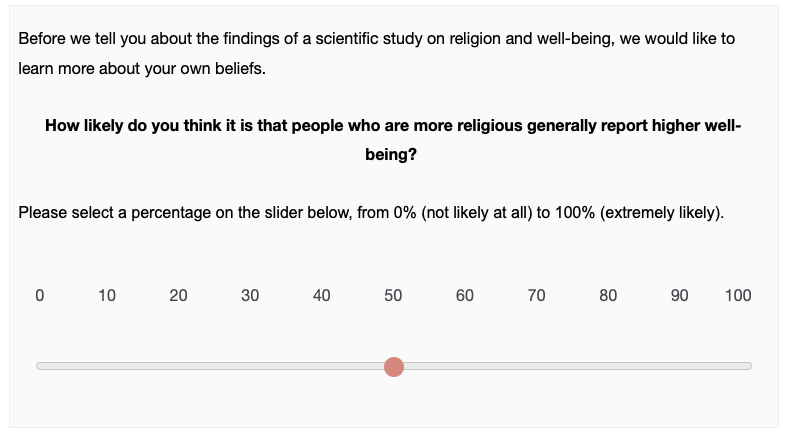



Participants are first introduced to the research question and research approach. In the single-analyst condition, a single team of six researchers analyzes the same dataset, and in the two multi-analyst conditions, six independent researchers analyze the same dataset. Importantly, in all conditions we emphasize in the last paragraph that there are a lot of choices to be made. Participants had to wait 30 seconds before proceeding to the next slide.



Here are the results we show participants. In the single-analyst condition, the team of six researchers concludes that religious people do indeed report higher well-being, and they find a 5% increase in well-being for every one point increase in religiosity. In the multi-consistent condition, the six independent researchers show consensus in that they all report a positive relationship, and the spread in their estimates is quite small; they range from 2% to 8%. In the multi-inconsistent condition, the six independent researchers do not show consensus, in that two of the scientists conclude that the relationship is negative, and four of the scientists conclude that the relationship is positive, and we can see that the spread in their estimates is quite large, ranging from -6% to 16%.


Results
Participants
Participants
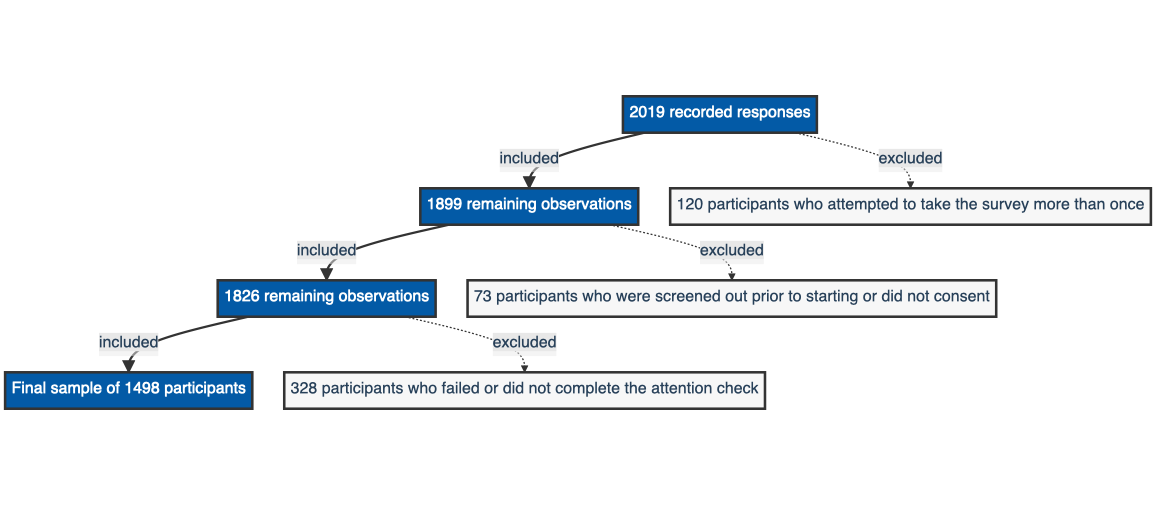
500 in the multi-consistent condition, 499 in the single-analyst and the multi-inconsistent condition
Main results
For the results, we regressed all outcomes on prior beliefs and condition, with the single-analyst condition as the reference category. So all results that I will show you control for prior beliefs and show the results for the two multi-analyst conditions compared to the single-analyst condition. I will now walk you through each individual aspect of this Figure.
Results: Multi-inconsistent
In line with our hypotheses, lay consumers of multi-analyst studies with inconsistent results
Results: Multi-inconsistent
In line with our hypotheses, lay consumers of multi-analyst studies with inconsistent results
Have lower posterior beliefs
Results: Multi-inconsistent
In line with our hypotheses, lay consumers of multi-analyst studies with inconsistent results
Have lower posterior beliefs
Find the results less credible
Results: Multi-inconsistent
In line with our hypotheses, lay consumers of multi-analyst studies with inconsistent results
Have lower posterior beliefs
Find the results less credible
Have less confidence in the aggregate estimate of 5%
Results: Multi-inconsistent
In line with our hypotheses, lay consumers of multi-analyst studies with inconsistent results
Have lower posterior beliefs
Find the results less credible
Have less confidence in the aggregate estimate of 5%
Believe the 5% estimate is more likely to stem from bias
Results: Multi-inconsistent
In line with our hypotheses, lay consumers of multi-analyst studies with inconsistent results
Have lower posterior beliefs
Find the results less credible
Have less confidence in the aggregate estimate of 5%
Believe the 5% estimate is more likely to stem from bias
Believe the 5% estimate is more likely to stem from error
Results: Multi-inconsistent
In line with our hypotheses, lay consumers of multi-analyst studies with inconsistent results
Have lower posterior beliefs
Find the results less credible
Have less confidence in the aggregate estimate of 5%
Believe the 5% estimate is more likely to stem from bias
Believe the 5% estimate is more likely to stem from error
For the additional exploratory measure, lay consumers of multi-analyst studies with inconsistent results
Believe the 5% estimate is more likely to stem from idiosyncratic choices
In line with out hypotheses, we find that lay consumers of multi-analyst studies with inconsistent results have lower posterior beliefs (you can see this estimate here), find the results less credible, have less confidence in the aggregate estimate of 5%, and believe this estimate is more likely to stem from bias, error, and discretion (which we define as idiosyncratic choices among multiple valid approaches, or what we researchers often refer to as researcher degrees of freedom).
Results: Multi-consistent
Contrary to our hypotheses, lay consumers of multi-analyst studies with consistent results
Results: Multi-consistent
Contrary to our hypotheses, lay consumers of multi-analyst studies with consistent results
Have lower posterior beliefs
Results: Multi-consistent
Contrary to our hypotheses, lay consumers of multi-analyst studies with consistent results
Have lower posterior beliefs
Believe the 5% estimate is more likely to stem from error
Results: Multi-consistent
Contrary to our hypotheses, lay consumers of multi-analyst studies with consistent results
Have lower posterior beliefs
Believe the 5% estimate is more likely to stem from error
We found no significant effects on
Results: Multi-consistent
Contrary to our hypotheses, lay consumers of multi-analyst studies with consistent results
Have lower posterior beliefs
Believe the 5% estimate is more likely to stem from error
We found no significant effects on
Credibility of the results
Results: Multi-consistent
Contrary to our hypotheses, lay consumers of multi-analyst studies with consistent results
Have lower posterior beliefs
Believe the 5% estimate is more likely to stem from error
We found no significant effects on
Credibility of the results
Confidence in the aggregate parameter estimate of 5%
Results: Multi-consistent
Contrary to our hypotheses, lay consumers of multi-analyst studies with consistent results
Have lower posterior beliefs
Believe the 5% estimate is more likely to stem from error
We found no significant effects on
Credibility of the results
Confidence in the aggregate parameter estimate of 5%
Perceived impact of bias on the 5% estimate
Results: Multi-consistent
Contrary to our hypotheses, lay consumers of multi-analyst studies with consistent results
Have lower posterior beliefs
Believe the 5% estimate is more likely to stem from error
We found no significant effects on
Credibility of the results
Confidence in the aggregate parameter estimate of 5%
Perceived impact of bias on the 5% estimate
For the additional exploratory measure, lay consumers of multi-analyst studies with consistent results
Believe the 5% estimate is more likely to stem from idiosyncratic choices
Contrary to our hypotheses, we find that lay consumers of multi-analyst studies with consistent results also have lower beliefs and believe the 5% estimate is more likely to stem from error or from idiosyncratic choices. We found no significant effects on the credibility of the results, confidence in the aggregate parameter estimate of 5%, and the perceived impact of bias on the estimate.
Note. Prior beliefs are displayed in blue; posterior beliefs are displayed in orange. The respective boxes display the lower quartiles, medians, and upper quartiles of prior and posterior beliefs by condition.
It is worth noting on the basis of Figure 2 and a post-hoc, paired t-test that, while multi-analyst studies with consistent results perform worse or no better than single-analyst studies on all measures, there is a significant, positive effect of the findings on posterior beliefs within the multi-consistent condition: i.e., beliefs in the research hypothesis are greater after reading the multi-consistent study results, M_d=4.75, p<.001. This finding clarifies that multi-analyst studies are not necessarily bad in absolute terms — however, when comparing to conventional, single-analyst scientific research, crowdsourced data analysis does not seem to provide an improvement in the sway and credibility of scientific research to lay consumers.
Discussion
Compared to a single estimate, we find no evidence that crowd estimates improve lay perceptions of scientific findings
We conclude that, compared to a single estimate, we do not find evidence that crowd estimates improve lay perceptions of scientific findings. In the future, we are curious to explore whether it might be aversion to variability that explains these findings, and what the perceptions of scientists are. We also believe that in the future it is important for crowd scientists to consider how -- for example, by drawing from research on science communication -- to tackle science skepticism and effectively communicate variable crowd estimates to lay consumers.
From the proliferation of big team science and large-scale replication initiatives to preregistration and registered reports, several scientific fields have undergone significant reform with the well-intended goal of improving the reliability of scientific research. The multi-analyst approach has many worthy uses, from demonstrating the arbitrariness and impact of individual analytic choices to acknowledging the inherent variability of results and averaging across idiosyncratic analytic choices to obtain more accurate parameter estimates. However, as with any real-world intervention, scientific reform can have unintended consequences. Here, we focus on the effects of crowdsourcing data analysis, and find that the multi-analyst approach may have an unintended consequence.
While partly instituted with the goal of improving the credibility of scientific research, lay consumers appear to resist the inherent variability and lack of consensus that often reflect the reality of multi-analyst research. To our surprise, even when results generated by independent analysts are largely consistent, lay consumers are less likely to believe in the reported phenomenon and more likely to think that the findings stem from error or idiosyncratic choices.
Compared to a single estimate, we find no evidence that crowd estimates improve lay perceptions of scientific findings
Future directions
Does variability aversion explain the findings?
We conclude that, compared to a single estimate, we do not find evidence that crowd estimates improve lay perceptions of scientific findings. In the future, we are curious to explore whether it might be aversion to variability that explains these findings, and what the perceptions of scientists are. We also believe that in the future it is important for crowd scientists to consider how -- for example, by drawing from research on science communication -- to tackle science skepticism and effectively communicate variable crowd estimates to lay consumers.
From the proliferation of big team science and large-scale replication initiatives to preregistration and registered reports, several scientific fields have undergone significant reform with the well-intended goal of improving the reliability of scientific research. The multi-analyst approach has many worthy uses, from demonstrating the arbitrariness and impact of individual analytic choices to acknowledging the inherent variability of results and averaging across idiosyncratic analytic choices to obtain more accurate parameter estimates. However, as with any real-world intervention, scientific reform can have unintended consequences. Here, we focus on the effects of crowdsourcing data analysis, and find that the multi-analyst approach may have an unintended consequence.
While partly instituted with the goal of improving the credibility of scientific research, lay consumers appear to resist the inherent variability and lack of consensus that often reflect the reality of multi-analyst research. To our surprise, even when results generated by independent analysts are largely consistent, lay consumers are less likely to believe in the reported phenomenon and more likely to think that the findings stem from error or idiosyncratic choices.
We conclude that, compared to a single estimate, we do not find evidence that crowd estimates improve lay perceptions of scientific findings. In the future, we are curious to explore whether it might be aversion to variability that explains these findings, and what the perceptions of scientists are. We also believe that in the future it is important for crowd scientists to consider how -- for example, by drawing from research on science communication -- to tackle science skepticism and effectively communicate variable crowd estimates to lay consumers.
Compared to a single estimate, we find no evidence that crowd estimates improve lay perceptions of scientific findings
Future directions
Does variability aversion explain the findings?
Perceptions of scientists?
We conclude that, compared to a single estimate, we do not find evidence that crowd estimates improve lay perceptions of scientific findings. In the future, we are curious to explore whether it might be aversion to variability that explains these findings, and what the perceptions of scientists are. We also believe that in the future it is important for crowd scientists to consider how -- for example, by drawing from research on science communication -- to tackle science skepticism and effectively communicate variable crowd estimates to lay consumers.
From the proliferation of big team science and large-scale replication initiatives to preregistration and registered reports, several scientific fields have undergone significant reform with the well-intended goal of improving the reliability of scientific research. The multi-analyst approach has many worthy uses, from demonstrating the arbitrariness and impact of individual analytic choices to acknowledging the inherent variability of results and averaging across idiosyncratic analytic choices to obtain more accurate parameter estimates. However, as with any real-world intervention, scientific reform can have unintended consequences. Here, we focus on the effects of crowdsourcing data analysis, and find that the multi-analyst approach may have an unintended consequence.
While partly instituted with the goal of improving the credibility of scientific research, lay consumers appear to resist the inherent variability and lack of consensus that often reflect the reality of multi-analyst research. To our surprise, even when results generated by independent analysts are largely consistent, lay consumers are less likely to believe in the reported phenomenon and more likely to think that the findings stem from error or idiosyncratic choices.
We conclude that, compared to a single estimate, we do not find evidence that crowd estimates improve lay perceptions of scientific findings. In the future, we are curious to explore whether it might be aversion to variability that explains these findings, and what the perceptions of scientists are. We also believe that in the future it is important for crowd scientists to consider how -- for example, by drawing from research on science communication -- to tackle science skepticism and effectively communicate variable crowd estimates to lay consumers.
Compared to a single estimate, we find no evidence that crowd estimates improve lay perceptions of scientific findings
Future directions
Does variability aversion explain the findings?
Perceptions of scientists?
Importance of science communication and communicating uncertainty
We conclude that, compared to a single estimate, we do not find evidence that crowd estimates improve lay perceptions of scientific findings. In the future, we are curious to explore whether it might be aversion to variability that explains these findings, and what the perceptions of scientists are. We also believe that in the future it is important for crowd scientists to consider how -- for example, by drawing from research on science communication -- to tackle science skepticism and effectively communicate variable crowd estimates to lay consumers.
From the proliferation of big team science and large-scale replication initiatives to preregistration and registered reports, several scientific fields have undergone significant reform with the well-intended goal of improving the reliability of scientific research. The multi-analyst approach has many worthy uses, from demonstrating the arbitrariness and impact of individual analytic choices to acknowledging the inherent variability of results and averaging across idiosyncratic analytic choices to obtain more accurate parameter estimates. However, as with any real-world intervention, scientific reform can have unintended consequences. Here, we focus on the effects of crowdsourcing data analysis, and find that the multi-analyst approach may have an unintended consequence.
While partly instituted with the goal of improving the credibility of scientific research, lay consumers appear to resist the inherent variability and lack of consensus that often reflect the reality of multi-analyst research. To our surprise, even when results generated by independent analysts are largely consistent, lay consumers are less likely to believe in the reported phenomenon and more likely to think that the findings stem from error or idiosyncratic choices.
We conclude that, compared to a single estimate, we do not find evidence that crowd estimates improve lay perceptions of scientific findings. In the future, we are curious to explore whether it might be aversion to variability that explains these findings, and what the perceptions of scientists are. We also believe that in the future it is important for crowd scientists to consider how -- for example, by drawing from research on science communication -- to tackle science skepticism and effectively communicate variable crowd estimates to lay consumers.
Compared to a single estimate, we find no evidence that crowd estimates improve lay perceptions of scientific findings
Future directions
Does variability aversion explain the findings?
Perceptions of scientists?
Importance of science communication and communicating uncertainty
Other suggestions?
We conclude that, compared to a single estimate, we do not find evidence that crowd estimates improve lay perceptions of scientific findings. In the future, we are curious to explore whether it might be aversion to variability that explains these findings, and what the perceptions of scientists are. We also believe that in the future it is important for crowd scientists to consider how -- for example, by drawing from research on science communication -- to tackle science skepticism and effectively communicate variable crowd estimates to lay consumers.
From the proliferation of big team science and large-scale replication initiatives to preregistration and registered reports, several scientific fields have undergone significant reform with the well-intended goal of improving the reliability of scientific research. The multi-analyst approach has many worthy uses, from demonstrating the arbitrariness and impact of individual analytic choices to acknowledging the inherent variability of results and averaging across idiosyncratic analytic choices to obtain more accurate parameter estimates. However, as with any real-world intervention, scientific reform can have unintended consequences. Here, we focus on the effects of crowdsourcing data analysis, and find that the multi-analyst approach may have an unintended consequence.
While partly instituted with the goal of improving the credibility of scientific research, lay consumers appear to resist the inherent variability and lack of consensus that often reflect the reality of multi-analyst research. To our surprise, even when results generated by independent analysts are largely consistent, lay consumers are less likely to believe in the reported phenomenon and more likely to think that the findings stem from error or idiosyncratic choices.
We conclude that, compared to a single estimate, we do not find evidence that crowd estimates improve lay perceptions of scientific findings. In the future, we are curious to explore whether it might be aversion to variability that explains these findings, and what the perceptions of scientists are. We also believe that in the future it is important for crowd scientists to consider how -- for example, by drawing from research on science communication -- to tackle science skepticism and effectively communicate variable crowd estimates to lay consumers.